🚦 The Core Decision: persist or merge?
Internally, when you call repository.save(entity), Spring Data JPA decides between two JPA operations:
entityManager.persist(entity)— used for new entitiesentityManager.merge(entity)— used for existing entities
The decision hinges on a single method:

This method determines whether the entity should be treated as new or not.
🧠 Default Behavior: How isNew() Works
The default implementation comes from JpaMetamodelEntityInformation, which uses the presence of a @Version field and the type of the ID to make the decision.
Here’s a simplified version of the logic:
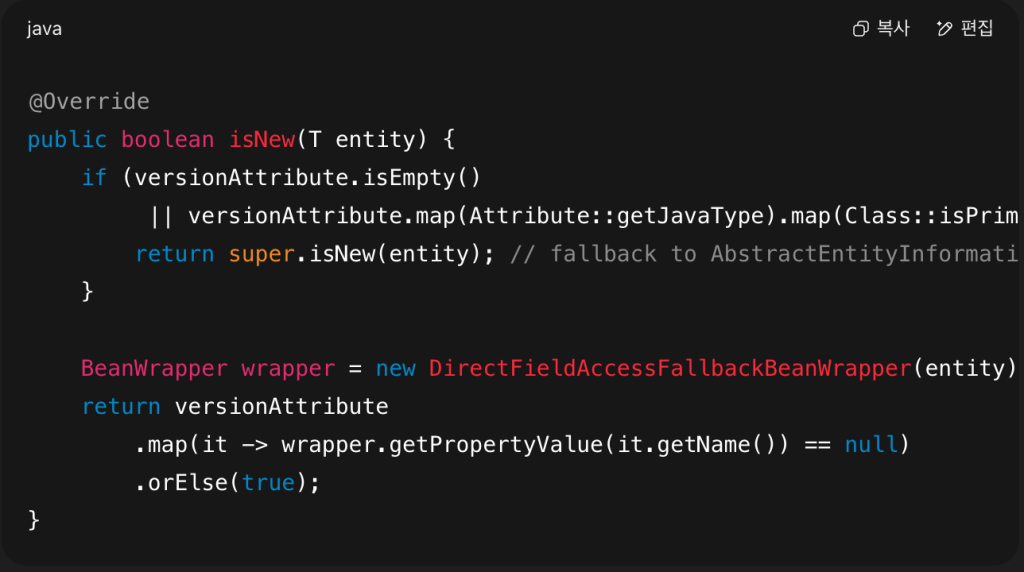
- If there’s no
@Versionfield or it’s a primitive type, Spring falls back toAbstractEntityInformation.isNew() - If it’s a wrapper type (e.g.
Long), it checks whether the version field isnull
Now let’s look at AbstractEntityInformation.isNew():
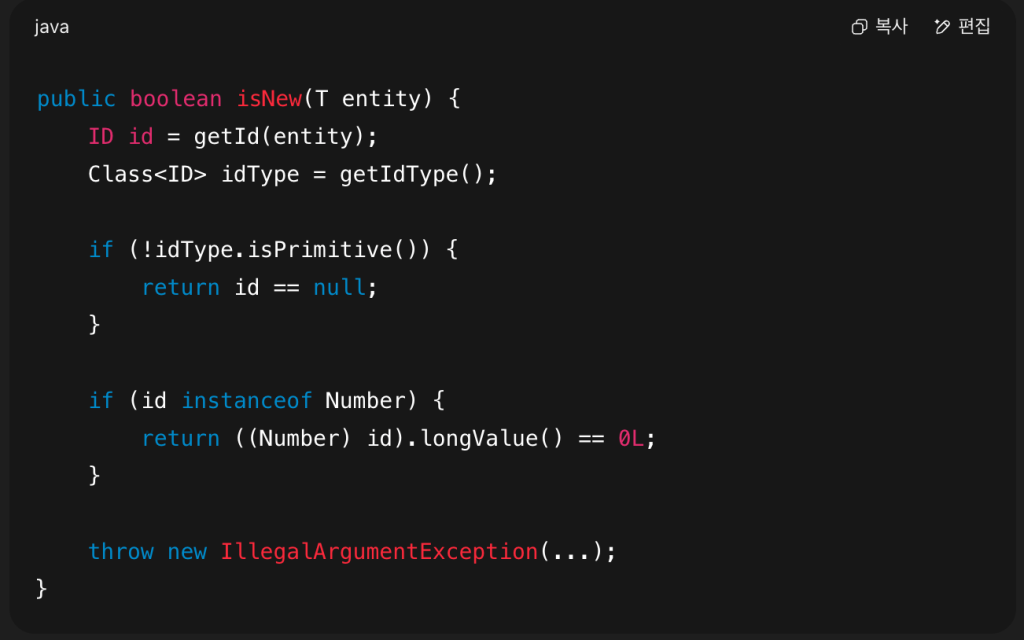
So, if your entity has:
- A wrapper ID (
Long,UUID, etc.), Spring treats it as new only if ID is null - A primitive ID (
long,int), it must be zero to be considered new
This works fine when IDs are auto-generated. But what if they aren’t?
🧩 What If You Set the ID Yourself?
If you assign the ID manually and skip @GeneratedValue, Spring Data will often think the entity is not new, even if it’s the first time you’re saving it. That’s because the ID is non-null and thus fails the “is new” check.
To solve this, you can implement the Persistable<T> interface in your entity:
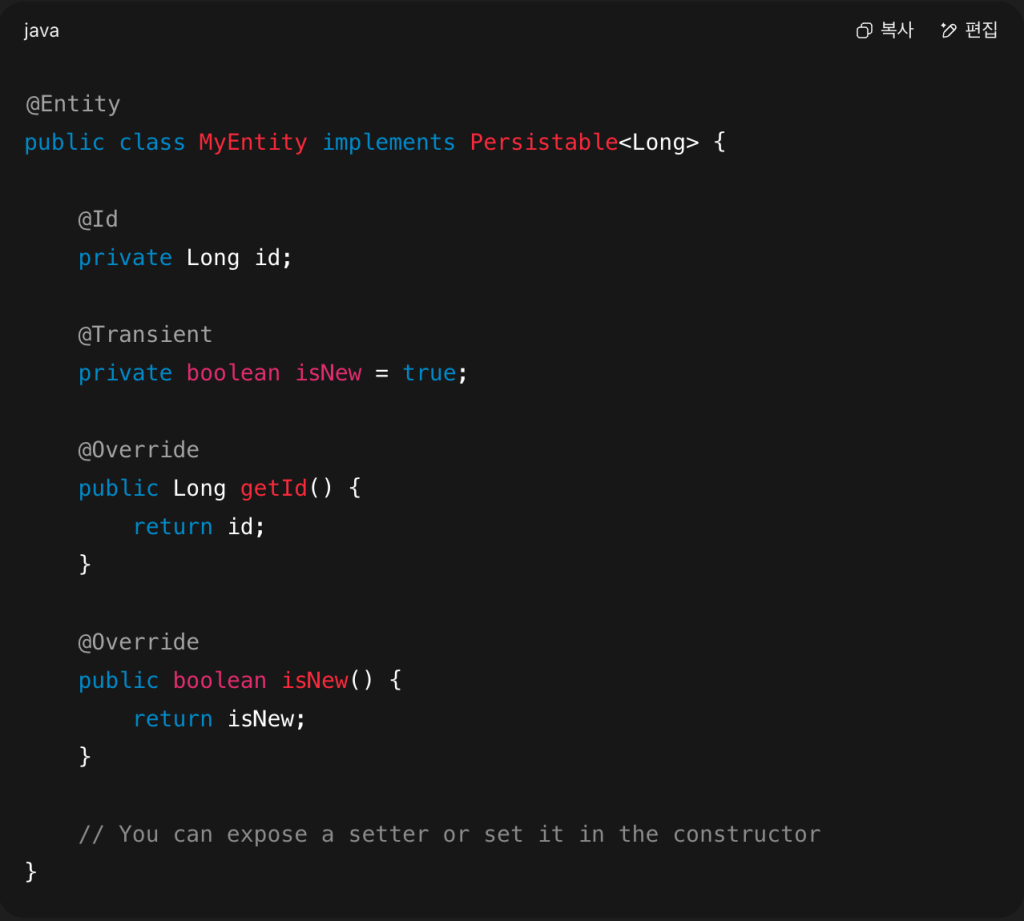
This tells Spring explicitly whether an entity is new. Now you’re in full control. Spring will use your logic in isNew() instead of relying on ID or version heuristics.
🧪 Why Does This Matter?
Let’s peek under the hood at how save() works in SimpleJpaRepository:
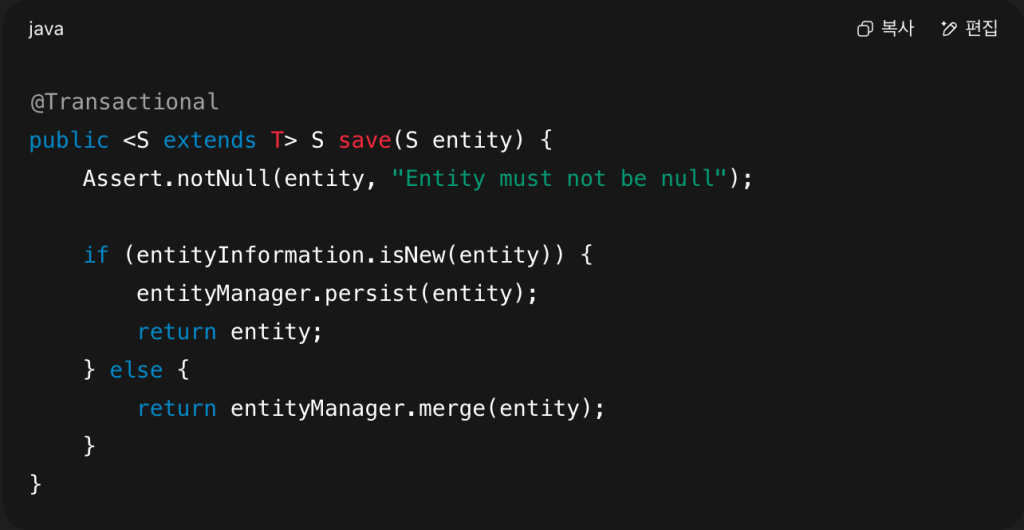
Here’s the gotcha:
If Spring thinks the entity is not new (because the ID is set), it uses merge().
Even if the entity doesn’t actually exist in the DB, merge() will:
- Try to fetch it first (wasted query)
- Then do an insert if not found (extra overhead)
This can be expensive, and even dangerous, depending on your context. Implementing Persistable gives you control to avoid that.
🧭 TL;DR Summary
| Scenario | Result |
|---|---|
@Id with @GeneratedValue | Handled automatically |
@Id manually assigned, no @Version | May be treated as existing |
@Version used (Long, not long) | Checked for null to decide |
Implements Persistable | You decide what’s “new” |
📘 Further Reading
- Hibernate docs: persist vs merge
- Spring Data JPA:
JpaEntityInformation - Spring source:
SimpleJpaRepository.save()and friends
🎯 Final Thoughts
Knowing how isNew() works isn’t just academic—it’s essential for:
- Writing efficient data access code
- Avoiding subtle bugs
- Building custom ID strategies
If you’re manually assigning IDs or doing clever things with detached entities, this is a concept you must have under your belt.
See you in the next post—maybe something like “persist() vs merge(): What’s really happening under the hood?” 🔧
